
Model Parallelism with Spark ML Tuning
Tuning machine learning models in Spark involves selecting the best performing parameters
for a model using CrossValidator or TrainValidationSplit. This process uses a parameter
grid where a model is trained for each combination of parameters and evaluated according to a
metric. Prior to Spark 2.3, running CrossValidator or TrainValidationSplit will train and
evaluate one model at a time in serial, until each combination in the parameter grid has been
evaluated. Spark of course will perform data parallelism throughout this process as usual, but
depending on your cluster configuration this could leave resources severely under-utilized. As
the list of hyperparameters increases, the time to complete a run can grow exponentially so it
is crucial that all available resources are maxed out. Introducing model parallelism allows
Spark to train and evaluate models in parallel, which can help keep resources utilized and
lead to dramatic speedups. Beginning with Spark 2.3 and SPARK-19357, this feature is
available but left to run in serial as default. This post will show you how to enable it,
run through a simple example, and discuss best practices.
New API in Spark ML
A new parameter is introduced in CrossValidator and TrainValidationSplit called
parallelism. It takes an integer value that must be >= 1, and defaults to 1 which will run
in serial just like before. A value greater than 1 roughly means the number of models that
can be evaluated in parallel. Here is how to set this parameter for a CrossValidator with
a level of parallelism of 10:
val cv = new CrossValidator()
.setEstimator(pipeline)
.setEvaluator(new BinaryClassificationEvaluator)
.setEstimatorParamMaps(paramGrid)
.setParallelism(10)
This does not necessary mean you will end up getting that level of parallelism, and
this is an important distinction to understand. The parallelism param controls how many
jobs that are sent to the Spark scheduler at a time. It is up to the scheduler to determine
the number of jobs to run for the resources available in the cluster. If your cluster does
not have the resources to accommodate all the jobs being scheduled, then new jobs will have
to wait until running jobs have completed. So the set level of parallelism might not be
achieved depending on how your cluster is configured and any other Spark jobs running.
Why Model Parallelism?
Since Spark excels at data parallelism, why not just optimize your configurations for that? It is true that if you know your cluster resources well and can anticipate the amount of data that will be used, you could probably tune your config pretty well to make good use of resources and run things at an optimum speed. However, this is not always easy to do and as ML pipelines get more complex, it is often that some stage will end up as a bottleneck. When that is the case, it’s ideal to have some jobs queued up ready to make use of free resources.
Example for Cross-Validation
Let’s work through a simple example that will demonstrate how model parallelism can pay off. This
example creates a ML pipeline with PCA and Linear Regression stages and makes a 4x4 param grid to
choose the best k for PCA and regParam for LR. The pipeline will be first be evaluated in
serial, with parallelism set to 1, and then with parallelism set to three 3.
Example Code
val pca = new PCA()
.setInputCol("data")
.setOutputCol("features")
val lr = new LinearRegression()
val pipeline = new Pipeline()
.setStages(Array(pca, lr))
val paramMaps = new ParamGridBuilder()
.addGrid(pca.k, Array(15, 20, 40, 75))
.addGrid(lr.regParam, Array(0.001, 0.003, 0.01, 0.03))
.build()
val eval = new TrainValidationSplit()
.setEstimator(pipeline)
.setEvaluator(new RegressionEvaluator())
.setEstimatorParamMaps(paramMaps)
.setTrainRatio(0.8)
.setParallelism(3)
Example Runs
The example is run in local mode on a laptop with 8 cores. Sample data is generated with 2 partitions
and the 4x4 param grid run with TrainValidationSplit will search for the best model out of 16
possible models. The dataset used consists of 100 features with 10,000 rows.
Serial Run
The first run is done with setParallelism(1) which is the default. This run will have
no model parallelism, so Spark will train and evaluate each of the 16 models one at a time until
all are evaluated and then choose the best model. Because the data has 2 partitions, Spark will
be able to use 2 cores to run tasks from the stages in parallel, but other cores will remain idle.
The image below was taken from the Spark UI of the event timeline and zoomed in to show the jobs running from the first model. There is 1 job being executed at a time, which consists of 2 tasks and using 2 cores.
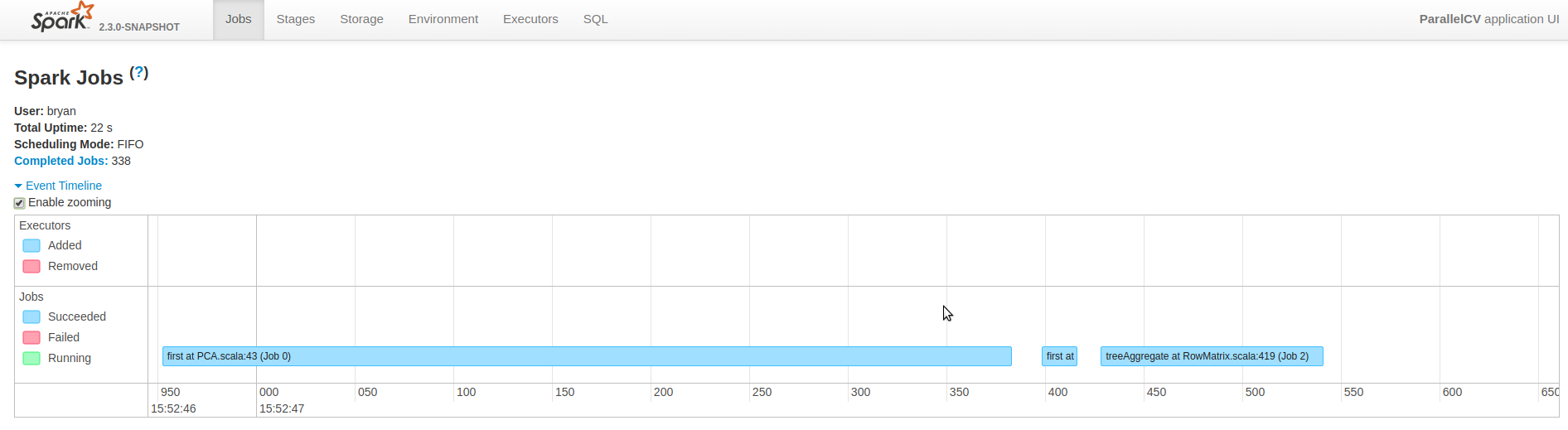 Spark UI of Serial Run Showing 1 Job Running
Spark UI of Serial Run Showing 1 Job Running
Parallel Run
The second run is done with setParallelism(3) that allows up to 3 models to be trained and evaluated
in parallel. Jobs for the first 3 models get queued because the value of parallelism is 3. The first
job from one of those models gets executed and the task takes up 2 cores, 1 for each of the data
partitions. While that task is running, since there are more cores available a job from another model
in the queue can also start. The number of cores being used is now 4, so one more job can be scheduled
from a third model. Since parallelism is capped at 3, the next model will have to wait to be queued
until all stages from one of the currently running models are completed.
The image below once again shows the Spark UI timeline but now 3 jobs from different models are running concurrently and making use of 6 cores.
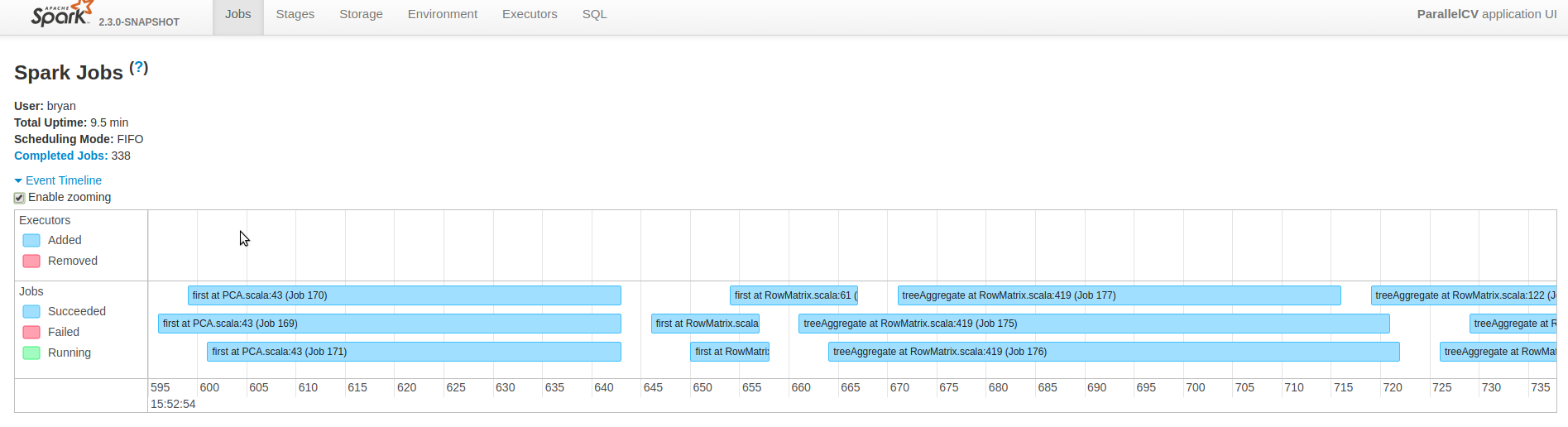 Spark UI of Parallel Run Showing 3 Jobs Running at Once
Spark UI of Parallel Run Showing 3 Jobs Running at Once
Timing data from these runs can be extremely varied because there are many things at play, especially in local mode on a single machine. On average for this simple example I normally see a speedup of about 2-3x. Speedups for a production cluster will also depend on lots of factors such as available resources, workload size, what kind of ML stages in the pipeline, etc.
Best Practices
We have seen that the parallelsim parameter controls the number of jobs sent to the Spark scheduler
which can help to make better use of available cluster resources, but choosing the right value can be
tricky. You want to make sure that as soon as resources are available the scheduler has a job it can
start, but at the same time it not good practice to overload the scheduler with jobs that will end up
waiting for a long time to start. The best approach is to shoot for having a few jobs in the queue to
make sure all available resources are utilized, without overdoing it. For a mid-sized cluster, a good
rule of thumb might be to set parallelism to a value of no more than 10, but it might take some
experiments to see what works best for you.